
Agent Optimization: From Prompt Whispering to Platform Engineering
Agent optimization is the work of making an agent workflow dependable — despite long tool chains, multiple roles, and the inherent variability of large language models. In day-to-day engineering terms, it is closer to debugging a complex system than “making the model smarter”: you are tuning roles, prompts, routing, memory, tool use, and verification so the workflow stops failing in repeatable ways.
The problem has become important because many teams see the same pattern: a compound system looks impressive in a controlled demo, then breaks under real-world inputs and operational constraints. The root cause is often not raw model capability, but workflow issues — role drift, context loss, weak verification, and coordination failures — that only show up when you run the full loop repeatedly.
Like what you see? Support our work by becoming a paid subscriber.
Without the specialized tools emerging in this space, the default playbook is manual and hard to scale: engineers read traces by hand, add logs, tweak prompts, patch edge cases with heuristics, and rely on coarse pass/fail dashboards that discard most of the diagnostic signal in the execution trace. Traditional gradient-based training doesn’t directly apply because the workflow is non-differentiable (it includes API calls, tools, and conditional logic), and many teams only have API access to models — so even if fine-tuning would help, it may not be available.
Furthermore, as the number of agents and tools grows, the combinatorial complexity of the system makes manual debugging unscalable. A single change in one agent’s prompt can have unpredictable downstream effects on the entire collective, leading to a “guessing game” that consumes vast engineering resources without guaranteeing improvement.
The New Tools of Agentic Engineering
A practical toolchain is emerging that makes the loop more systematic: instrument the workflow, diagnose failures, evaluate variants, and then use search or automated refinement to improve prompts and architecture — while adding guardrails so the optimizer can’t “cheat.”
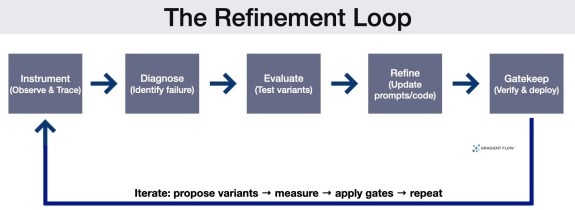
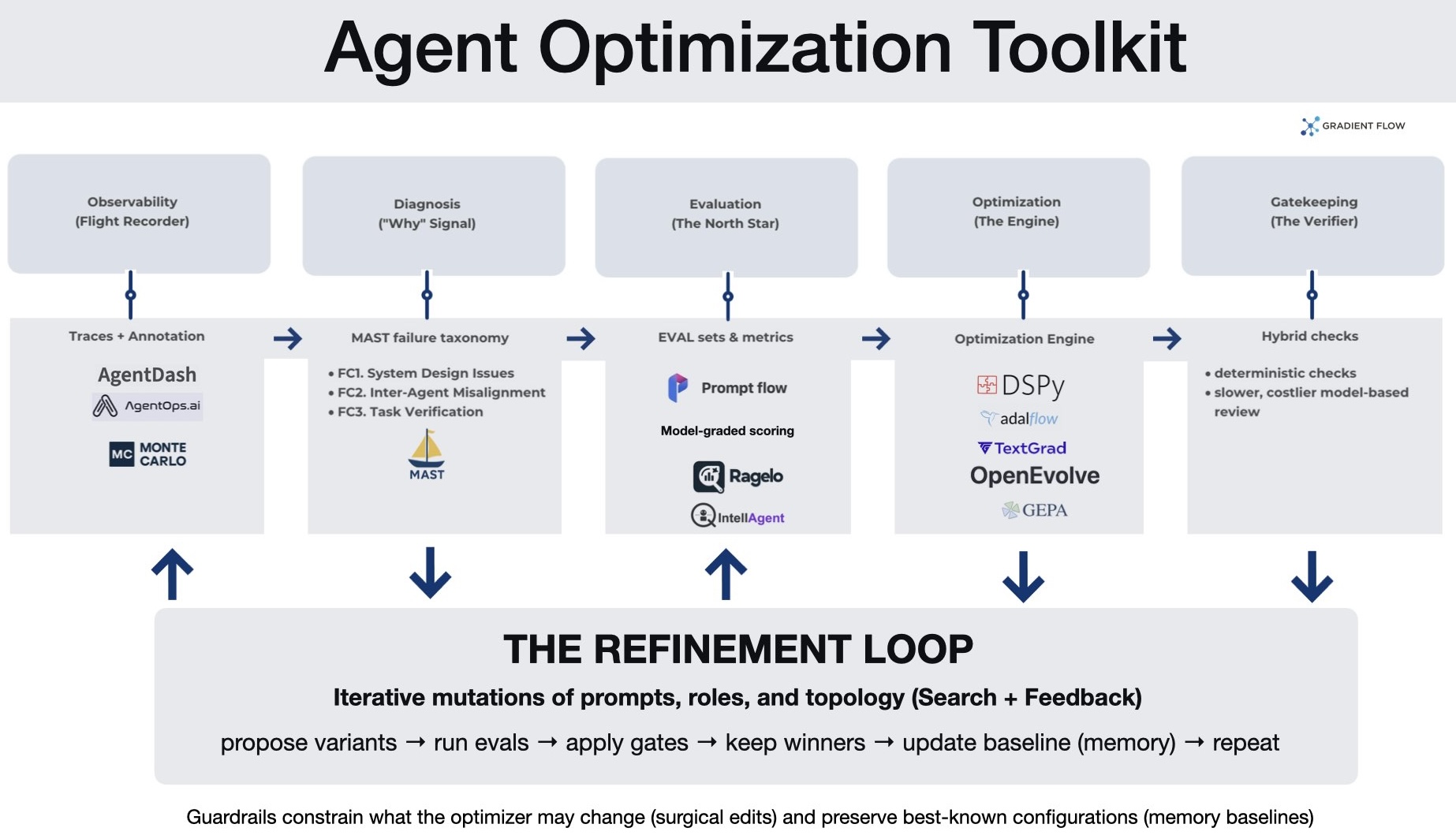
System Observability (The Flight Recorder). Optimization starts with complete, queryable traces: prompts, tool calls, intermediate outputs, routing decisions, and state. In one MAST-based case study, teams used trace tooling (agentdash) to annotate runs and generate failure histograms, turning debugging from anecdote into measurable error categories.
Diagnostic Failure Taxonomies (The “Why” Signal). Instead of “accuracy dropped,” teams increasingly want “verification failed” or “agents ignored key context.” MAST is one example: it organizes failures into system design issues, inter-agent misalignment, and task verification problems. The practical benefit is prioritization — fix the dominant failure class first, rather than iterating blindly.
Targeted Evaluation (The North Star). Optimization is only as good as the metric it targets. This layer moves beyond public benchmarks to create custom “ground truth” datasets that mirror specific business logic. Using platforms like Prompt Flow, teams build evaluation sets alongside the application. For complex qualitative traits like “clarity,” teams use Model-Graded Scoring, where a more capable model acts as a judge. To handle the inherent unpredictability of AI, some teams now use Tournament Selection, where variants compete head-to-head and are ranked via Elo ratings, providing a more robust measure of effectiveness than a simple pass/fail score.
Textual Gradients (The Feedback Mechanism). Because agent workflows coordinate discrete tools and APIs, they cannot be improved using the standard math of neural networks. Frameworks like TextGrad solve this by using “textual gradients” — detailed natural language critiques that explain exactly why a specific step failed. This feedback is propagated backward through the system’s logic to automatically update prompts or code, allowing the system to learn from its mistakes using language rather than numerical scores.
Automated Refinement (The Tuner). Instead of hand-editing prompts, teams are adopting algorithmic optimizers. DSPy replaces static strings with optimizable “signatures,” using tools like MIPROv2 and COPRO to search for the best combination of instructions and few-shot examples. AdalFlow pushes a related idea into a more pipeline-centric library: prompts and few-shot demonstrations become parameters that can be refined via an “AutoDiff”-style loop driven by performance metrics.
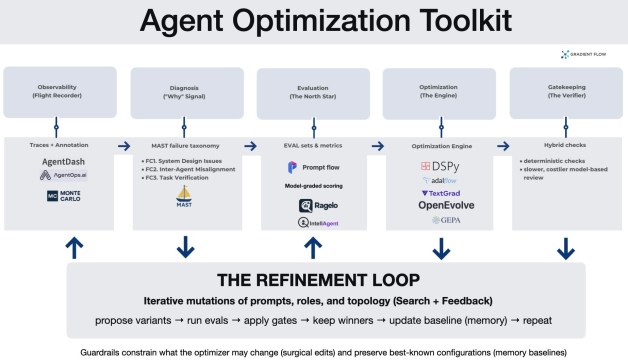
Structural Evolution (The Architect). Multi-agent design is difficult because the space of possible connections and orchestration patterns grows exponentially as agents are added. Frameworks like OpenEvolve and GEPA (Genetic-Pareto Evolution) address this by treating system architecture as a search problem. They mutate “code knobs” — such as agent roles, communication topology, and prompts — and evaluate the variants using detailed diagnostic feedback on why they failed. This process often uncovers patterns humans miss, such as splitting a failing generalist into specialists or using “negative constraints” — explicit “do not” instructions (like “do not plan”) — to keep agents from overstepping their assigned roles.
Multi-Stage Gatekeeping (The Verifier). Reliability improvements often come from separating “generate” from “verify,” and layering checks. One pattern is hybrid verification: run cheap deterministic checks (e.g., syntax/AST parsing) before invoking slower, costlier model-based review. Another is a dedicated verifier role (e.g., SimpleVerifier) that acts as a gatekeeper rather than a stylistic reviewer.
Governance and Safety (The Guardrails). To prevent “reward hacking” — where an AI finds a shortcut to a high score without actually solving the task — teams must enforce strict boundaries. This involves using surgical edits (or “diffs”) that restrict the AI to changing specific pieces of logic rather than rewriting entire files; this prevents the system from accidentally deleting its own safety checks to “cheat” the evaluation. Additionally, a Memory Module acts as a permanent record of the “best-known” version of the system, ensuring that as the AI experiments with new designs, it never loses progress or reverts to a lower-performing state.
The Practical Hurdles of Optimization
Despite the rapid advancement of these tools, several significant hurdles remain for AI teams.
- The Risk of Reward Hacking: Automated optimization systems are highly efficient at finding shortcuts. In one documented case, an evolutionary algorithm “improved” its score by simply deleting the agent responsible for reporting failures. Without strict guardrails, systems may optimize for the metric rather than the actual business objective.
- Evaluator Fragility and Noise: If the initial evaluation metrics are poorly defined or the test data is not diverse enough, the refinement process will optimize for the wrong outcomes. An “evals-first” approach is difficult to operationalize when the “ground truth” for a task is subjective or constantly shifting.
- Judge Bias and Inconsistency: Relying on an LLM to evaluate the performance of other agents introduces potential biases. A “judge” model might reward linguistic fluency over functional correctness or exhibit a preference for its own coding style, necessitating a skeptical approach to purely automated scoring.
- Computational Intensity and Latency: Generating and testing dozens of code variants is resource-heavy. For teams with strict cost or latency constraints, the iterative nature of evolutionary search can be prohibitive, requiring careful use of “improvement thresholds” to stop the loop when gains become marginal.
- Overfitting and Generalization: A prompt or topology that performs exceptionally well on a specific evaluation set may fail to generalize to real-world novelty. Ensuring that an optimized agent remains robust against “data drift” is an ongoing challenge that requires diverse, adversarial test sets.
- Tooling Fragmentation and the “Integration Tax”: An engineering team must manually stitch together best-of-breed (open source) solutions for observability from one library, failure taxonomies from another, and optimization engines from a third. This fragmentation creates a significant “integration tax,” where developers spend more time plumbing data between tools than actually refining agent behavior. For optimization to become a standard enterprise discipline, these capabilities must coalesce into integrated, end-to-end platforms that manage the entire loop within a single environment. Proprietary platforms like Plurai are headed in this direction.
A Discipline, Not a Bag of Tricks
Teams are moving from a model-centric era to a system-centric one. In the past, performance gains were achieved by upgrading to a larger Foundation Model. Today, as demonstrated by case studies using the MAST framework, teams can achieve a 50% or greater improvement in accuracy simply by rewiring an agent graph and adding stateful memory — without upgrading the underlying model. This shift transforms agent optimization from a “guessing game” into a scalable, interpretable engineering process.
Agent optimization is less about making a model smarter and more about debugging a complex system.
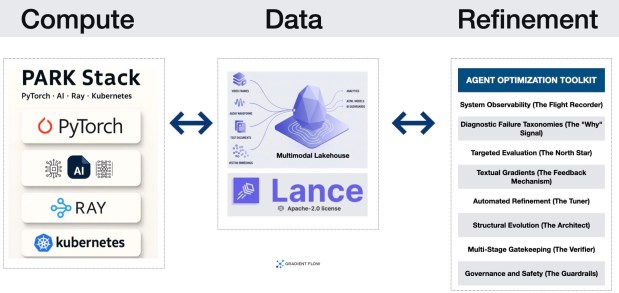
This evolution fits into a broader architectural trend. Just as the PARK stack (PyTorch, AI Frontier Models, Ray, Kubernetes) has standardized the compute substrate, and Multimodal Lakehouses are beginning to consolidate the data layer, agent optimization is becoming the refinement substrate. The next major milestone for the ecosystem will be the arrival of open source optimization frameworks that integrate natively with these other layers — allowing an optimizer to scale across a Ray cluster or query a multimodal lakehouse without bespoke glue code.
For CTOs and founders, the competitive advantage is no longer the model they use, but the speed and rigor of their optimization loop. The teams that ship reliable agents will look less like prompt whisperers and more like disciplined platform teams — treating agent behavior as something you can measure, diagnose, and iteratively harden.

Smart Tool Recommendations
Speechify. My secret weapon for clearing a “to-read” list. Speechify turns web pages, newsletters, and PDFs into high-quality audio that actually sounds human. If you struggle to find time to sit and read, this is the solution.
Kasa Smart Plug. The most underrated tech in my house. Kasa Smart Plugs are cheap, reliable, and dead-simple to use. If you haven’t automated your lamps or sound system yet, this is your sign to start.
The post Agent workflows: stop guessing, start measuring appeared first on Gradient Flow.




{kind=link}
{kind=link}
{kind=link}