
How Leaders Are Using RL to Build a Competitive AI Advantage
I have long been fascinated by reinforcement learning (RL), but have always viewed it as complex and beyond the reach of most enterprise AI teams. That perception began to shift slightly earlier this year after a conversation with Travis Addair, co-founder of Predibase, about “reinforcement fine-tuning”—using RL methods to sharpen large language models for specific, objective tasks. The conversation hinted that RL was inching toward practical territory, enough to keep it firmly on my radar.
Four months later, an Anyscale comparison of RL libraries for LLMs showed just how quickly the landscape is evolving. While reinforcement learning from human feedback (RLHF) was the first mainstream application—used primarily to align models with human preferences—the field has expanded dramatically. Today, RL is driving the development of advanced reasoning models and autonomous agents that can solve complex, multi-step problems.
This trend has become more apparent in recent months. At industry events and in technical presentations, companies are beginning to detail their explorations of RL for foundation models. The current landscape, however, is a mixed bag: a handful of compelling case studies—still largely from technology firms—have appeared, alongside some nascent tooling aimed at improving accessibility. But these are early days, and considerable work remains to make such techniques practical for most enterprise teams. The significance of these early efforts lies in the direction they signal for enterprise AI.
Gradient Flow is a reader-supported publication. Support our work by becoming a paid subscriber 
From Prompt Engineering to Automated Feedback
The common practice of refining foundation models through manual prompt engineering often proves unsustainable. Teams can become trapped in a frustrating cycle, where tweaking a prompt to correct one error inadvertently introduces another. A Fortune 100 financial services organization discovered this firsthand when working with Adaptive ML to analyze complex financial documents like 10-K reports, where mistakes could expose the institution to significant legal risks.
Traditional prompt engineering led to an endless loop of fixes and new errors, so the system never reached production-level reliability. The team turned to RL, fine-tuning a Llama model with an automated system of verifiers that checked responses against source documents, which eliminated the need for manual prompt engineering. The resulting model, now better able to reason independently rather than simply memorize responses, doubled its effectiveness, boosting its win rate against GPT-4o from a baseline of 27% to 58%.
This shift illustrates a fundamental advantage of modern RL approaches: they allow teams to move from providing static examples to creating dynamic feedback systems. As Travis Addair explained to me, the user’s role evolves from data labeler to critic, providing targeted feedback on what the model does well and where it falls short. For objective tasks like code generation, this feedback can be completely automated through unit tests that verify correctness, allowing models to explore different solutions and learn from trial and error.

Teaching Models to Reason, Not Just Memorize
One of RL’s most powerful applications involves teaching models to reason through problems step-by-step. Enterprise AI company Aible uses a compelling analogy, contrasting “pet training” with “intern training.” Traditional supervised fine-tuning resembles pet training—you reward or punish based solely on the final output. Reinforcement learning enables intern training, where you can provide feedback on intermediate reasoning steps, much like mentoring a human employee.
The results can be dramatic. By providing feedback on just 1,000 examples—a process costing only $11 in compute—Aible saw a model’s accuracy on specialized enterprise tasks leap from a mere 16% to 84%. The key was shifting from binary feedback on final outputs to granular guidance on reasoning steps, allowing users to identify and correct subtle logical errors that might be missed when evaluating only end results.
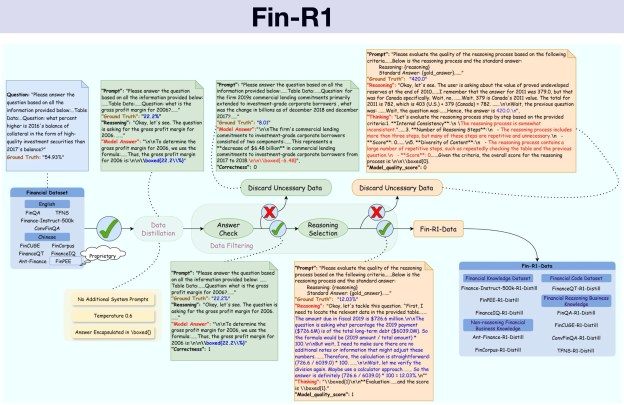
Financial institutions are seeing similar breakthroughs. Researchers developed Fin-R1, a specialized 7-billion parameter model engineered specifically for financial reasoning tasks. By training on a curated dataset of financial scenarios with step-by-step reasoning chains, the compact model posted scores of 85.0 on ConvFinQA and 76.0 on FinQA, surpassing the performance of much larger, general-purpose models. The approach addresses critical industry requirements including automated compliance checking and robo-advisory services, where regulatory bodies demand transparent, step-by-step reasoning processes.
Building Autonomous Business Agents
The frontier application for RL involves training autonomous agents to execute complex business workflows. This typically requires creating safe simulation environments—what practitioners call “RL gyms”—where agents can practice multi-step tasks without affecting production systems. These environments replicate real business applications like Salesforce or HubSpot, capturing user interface states and system responses to enable safe experimentation.
Chinese startup Monica developed Manus AI using this approach, creating a sophisticated multi-agent system with specialized components: a Planner Agent for task breakdown, an Execution Agent for implementation, and a Verification Agent for quality control. Through RL training, Manus learned to adapt its strategies dynamically, achieving state-of-the-art performance on the GAIA benchmark for real-world task automation while exceeding 65% success rates compared to competitors.
In e-commerce, researchers at eBay took a novel approach to multi-step fraud detection by reframing it as a sequential decision-making problem across three stages: pre-authorization screening, issuer validation, and post-authorization risk evaluation. Their breakthrough was using large language models to automatically generate and refine the feedback mechanisms for training, eliminating the traditional bottleneck of manual reward engineering. Validated on over 6 million real eBay transactions across six months, the system delivered a 4 to 13 percentage point increase in fraud detection precision. It accomplished this while keeping response times under 50 milliseconds, making it suitable for real-time processing.
Note that the infrastructure challenges of implementing RL at scale remain significant. Anthropic’s partnership with Surge AI to train Claude illustrates the specialized platforms required for production RLHF. Traditional crowdsourcing platforms lacked the expertise needed to evaluate sophisticated language model outputs, creating bottlenecks in Anthropic’s development pipeline. Surge AI’s specialized platform addressed these challenges through domain expert labelers and proprietary quality control algorithms, enabling Anthropic to gather nuanced human feedback across diverse domains while maintaining the data quality standards essential for training state-of-the-art models.

Enterprise-Scale Implementation
The Apple Intelligence foundation models represent one of the largest-scale RL deployments in consumer technology. Apple developed two complementary models—a 3-billion parameter on-device model and a scalable server-based model—using the REINFORCE Leave-One-Out (RLOO) algorithm. The company’s distributed infrastructure for RL cut the number of required devices by 37.5% and reduced compute time by 75% compared to conventional synchronous training. More importantly, the measurable impact was substantial: RL delivered 4-10% improvements across performance benchmarks, with particularly strong gains in instruction following and helpfulness—the interactive aspects users actually experience.
Similarly, enterprise-focused AI company Cohere developed Command A through an innovative decentralized training approach. Rather than training a single massive model, they developed six domain-specific expert models in parallel—covering code, safety, retrieval, math, multilingual support, and long-context processing—then combined them through parameter merging. Multiple RL techniques refined the merged model’s performance, raising its human preference rating against GPT-4o from 43.2% to 50.4% on general tasks, with even larger gains on reasoning and coding.

For global enterprise applications, cultural complexity creates unique challenges for RL implementation. A major North American technology company partnered with Macgence to implement RLHF across diverse global markets spanning Asia, Africa, Europe, and the Americas. The project processed 80,000 specialized annotation tasks encompassing multilingual translation, bias mitigation, and cultural sensitivity—challenges that traditional supervised learning approaches proved insufficient to handle. The complexity of cultural nuance and bias detection required iterative human feedback learning that could only be achieved through reinforcement learning methods.
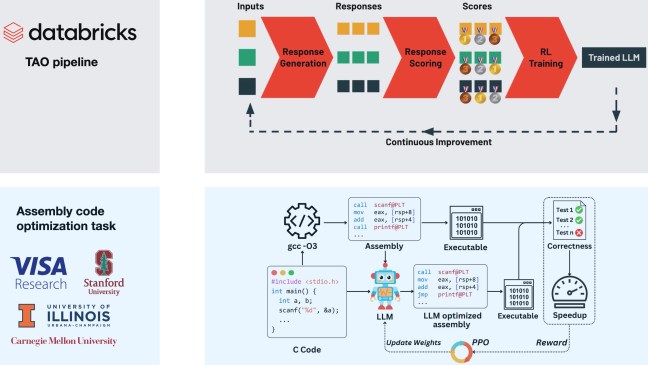
Simultaneously, enterprise platforms are making RL techniques more accessible. Databricks introduced Test-time Adaptive Optimization (TAO), which enables organizations to improve model performance using only the unlabeled usage data they already generate through their AI applications. Unlike traditional methods requiring expensive human-labeled training data, TAO leverages reinforcement learning to teach models better task performance using historical input examples alone. By creating a data flywheel—where deployed applications automatically generate training inputs—the approach enables cost-effective open-source models like Llama to achieve quality levels comparable to expensive proprietary alternatives.
The Research Pipeline
Despite promising case studies I’ve highlighted, RL remains a niche capability for most organizations. Many advanced implementations come from technology companies like Apple, Cohere, and Anthropic. It’s still rare to come across teams able to use RL for LLMs and foundations models.
RL research initiatives now cover an unexpectedly broad range of problems. Visa researchers used RL to train models for assembly code optimization, achieving a 1.47x average speedup over industry-standard compilers by discovering hardware-specific optimizations that rule-based systems missed. At MIT and IBM, researchers developed systems that learned to automatically allocate computational resources to harder problems—an emergent capability not explicitly programmed. Other teams are exploring applications from circuit design automation to mathematical proof generation.
RL can create a data flywheel where deployed applications automatically generate their own training inputs for continuous improvement.
The open-source ecosystem highlighted in Anyscale’s analysis—including frameworks like SkyRL, verl, and NeMo-RL—represents promising progress toward democratizing these capabilities. However, as Travis Addair noted in our conversation, significant work remains in creating interfaces that allow domain experts to guide training processes without requiring deep RL expertise.
The convergence of increasingly capable foundation models, proven RL techniques, and emerging tooling suggests we might finally be at an inflection point. As reasoning-enhanced models become standard and enterprises demand more sophisticated customization capabilities, reinforcement learning appears poised to transition from specialized research technique to essential infrastructure for organizations seeking to maximize their AI investments.
Learn the fundamentals and share best practices for building large-scale AI applications at Ray Summit, where the global AI community gathers to advance machine learning and AI.

The post The data flywheel effect in AI model improvement appeared first on Gradient Flow.


